【导读】无需人工标示�,�,�,,吞下17亿张图片�,�,�,,Meta用自监视学习炼出「视觉万能王」!NASA已将它送上火星�,�,�,,医疗、卫星、自动驾驶领域整体欢悦�。。�。�。
17亿张图片�,�,�,,Meta训出70亿参数「视觉巨兽」DINOv3�,�,�,,彻底开源了!
经由自监视学习(SSL)训练�,�,�,,DINOv3可天生强壮且高区分率的图画特征�。。�。�。
在多个密布推测使掷中�,�,�,,这是简单牢靠的视觉主干网络第一次逾越专用解决计划�。。�。�。
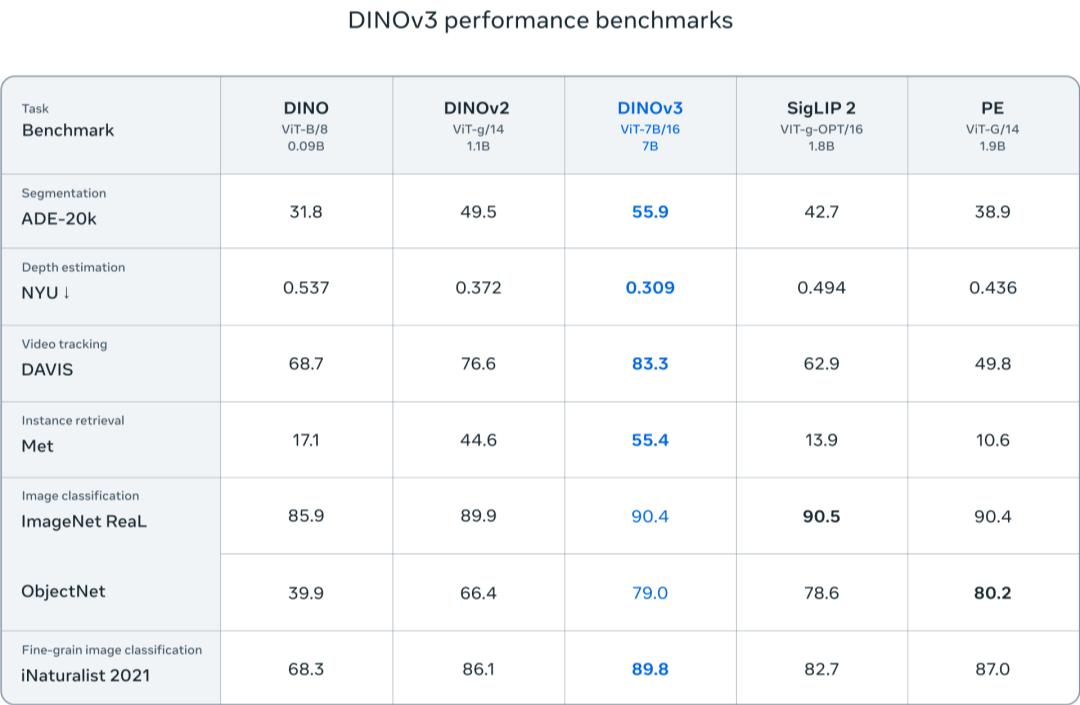
DINOv3重新界说核算机视觉功效天花板�,�,�,,在多个基准考试中改写或迫临最佳作用!
美国的NASA以致已在火星探讨上用上了DINOv3�。。�。�。这是真上天了!
就在我们以为Meta在AI角逐上被筛选之时�,�,�,,Meta这次总算意气高昂�。。�。�。

并且�,�,�,,这次Meta是真开源:DINOv3不但可商用�,�,�,,还开源了完好的预训练主干网络、适配器、训练与评价代码等「全流程」�。。�。�。

项目地点:https://github.com/facebookresearch/dinov3
悉数checkpoint:https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009
DINOv3亮点如下:
SSL支持在无需标签的情形下对含17亿张图画、70亿参数的模子举行训练�,�,�,,适用于标示资源稀缺的场景�,�,�,,包括卫星图画�。。�。�。
天生超卓的高区分率特征�,�,�,,并在密布推测使命上完结最先进的功效�。。�。�。
多样化的视觉使命和领域运用�,�,�,,悉数选用冻住主干(无需微调)�。。�。�。
包括蒸馏后更小的模子(ViT-B、ViT-L和ConvNeXt 变体�,�,�,,以完结迅速安排�。。�。�。
自监视学习的新胜利
自监视学习无需人工标示数据即可自力学习�,�,�,,已成为现代机械学习领域的主导范式�。。�。�。
狂言语模子兴起全在于此:经由在海量文本语料库上举行预训练来获取通用表征�。。�。�。可是�,�,�,,核算机视觉领域的开展却相对滞后�,�,�,,由于现在最强壮的图画编码模子在训练时仍严肃依赖人工天生的元数据�,�,�,,例如网络图片问题�。。�。�。
DINOv3改变了这一切:
DINOv3提出了新的无监视学习手艺�,�,�,,极大地镌汰了训练所需的时刻和资源�。。�。�。
这种免标示的步伐特殊适用于标示稀缺、资源高昂或基础无法获取标示的场景�。。�。�。例如�,�,�,,运用卫星印象预训练的 DINOv3主干网络�,�,�,,在树冠高度估量等下游使掷中体现优异�。。�。�。
不但能加速现有运用的开展�,�,�,,DINOv囚笼极速特攻无删减版;之光电影无删减3尚有或许解锁全新的运用场景�,�,�,,推动医疗保健、情形监测、自动驾驶、零售、制作等职业的前进�,�,�,,完结更精准、高效的大妄想视觉相识�。。�。�。
亘古未有:自监视学习逾越弱监视
DINOv3再次改写了里程碑——首次证实自监视学习(SSL)模子能够在普遍使掷中逾越弱监视模子的体现�。。�。�。
DINOv3一连了DINO算法�,�,�,,不需求任何元数据输入�,�,�,,但这次所需训练算力仅为以往步伐的一小部分�,�,�,,却仍然能产出极端强壮的视觉根底模子�。。�。�。

凭仗这些全新改善�,�,�,,在竞赛强烈的下游使命(如在冻住权重条件下的目的检测)中�,�,�,,DINOv3也能取得其时最优体现�。。�。�。
这意味着钻研者和开发者无需为特定使命举行微调�,�,�,,即可将其直接运用于更普遍、更高效的场景�。。�。�。
别的�,�,�,,DINO步伐并未针对特定图画模态举行优化�,�,�,,它不但适用于网络图画�,�,�,,还能推行到那些标示极端难题或资源高昂的领域�。。�。�。
DINOv2现已运用海量无标示数据�,�,�,,支持了安排病理学、内窥镜及医学印象等偏向简直诊与科研事情�。。�。�。而在卫星与航空印象领域�,�,�,,数据量重大且杂乱�,�,�,,使人工标示简直不可行�。。�。�。
DINOv3能够将这些丰富的数据集用于训练一个通用主干网络(single backbone)�,�,�,,并跨差别类型的卫星图画�,�,�,,完结情形监测、都会妄想、灾祸应对等多种运用�。。�。�。
DINOv3已在实践国际爆发了影响�。。�。�。
国际资源钻研所(WRI) 正在运用新模子监测森林采伐并支持生态修正�,�,�,,协助外地整体维护软弱的生态系统�。。�。�。依托DINOv3�,�,�,,WRI剖析卫星印象�,�,�,,检测受影响生态区域的树木损失和土地运用改变�。。�。�。
DINOv3带来的精度提高�,�,�,,使其能够自动化天气金融拨款流程�,�,�,,经由验证修正作用来下降生意资源�,�,�,,加速资金流向外地小型安排�。。�。�。
例如�,�,�,,与DINOv2较量�,�,�,,在对肯尼亚某区域的树冠高度举行丈量时�,�,�,,运用卫星与航空印象训练的DINOv3将平均误差从4.1 米降至1.2 米�。。�。�。
无需微调也能完结高效Scaling
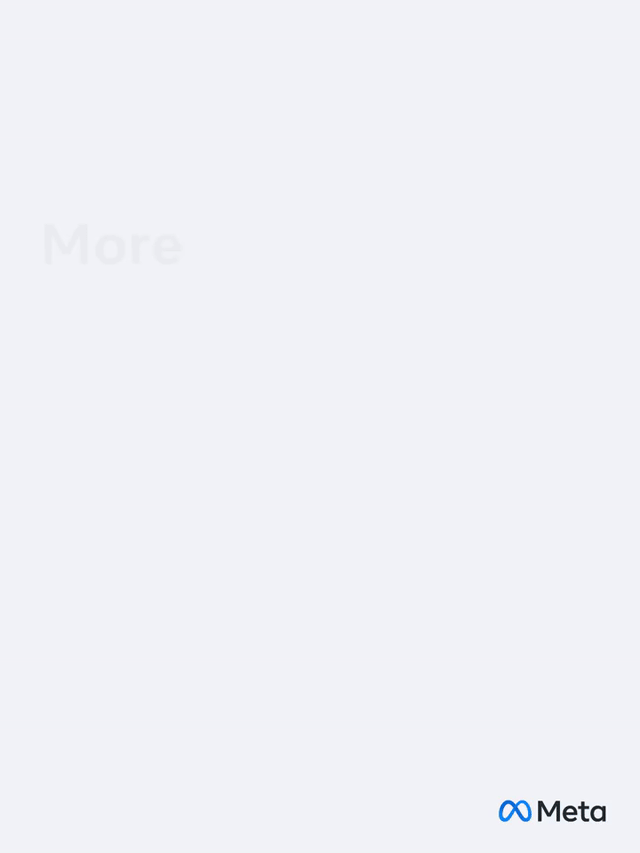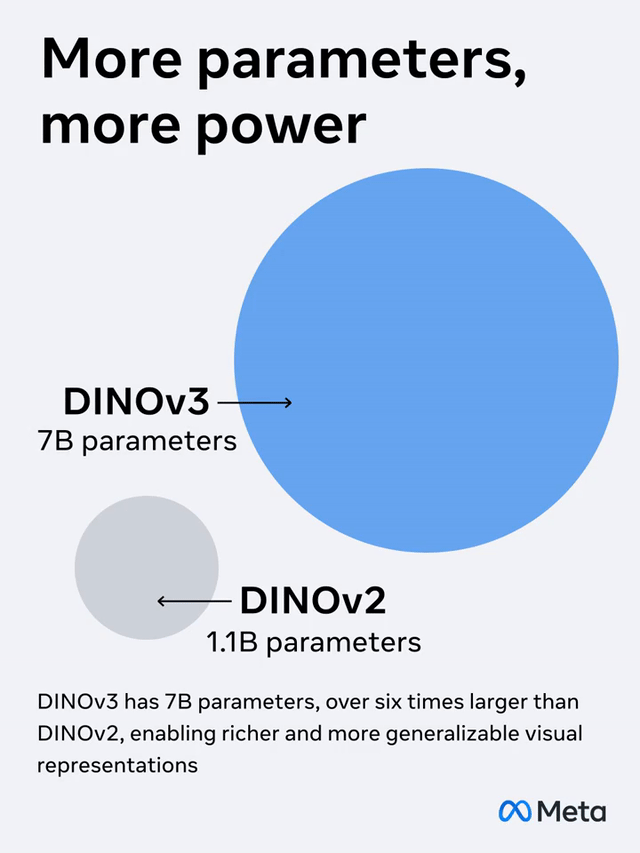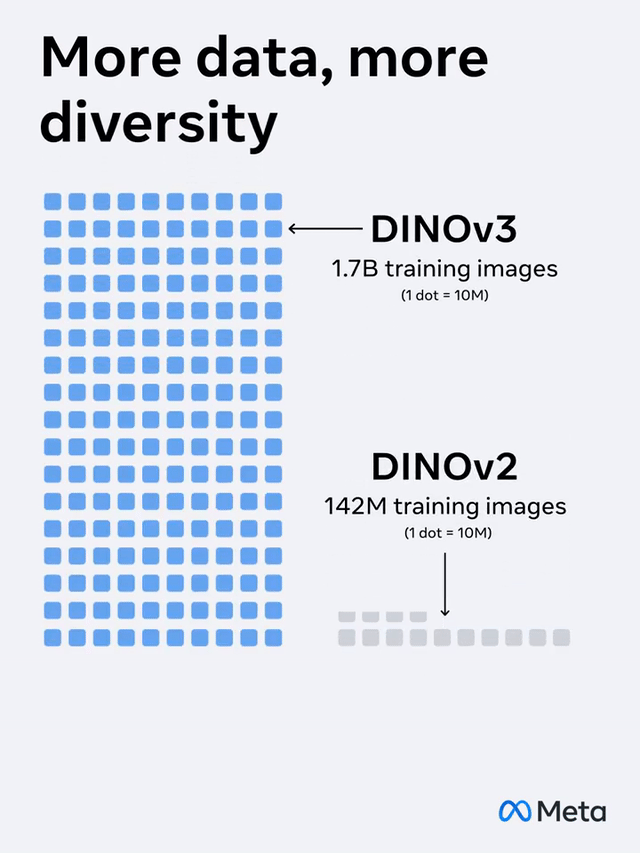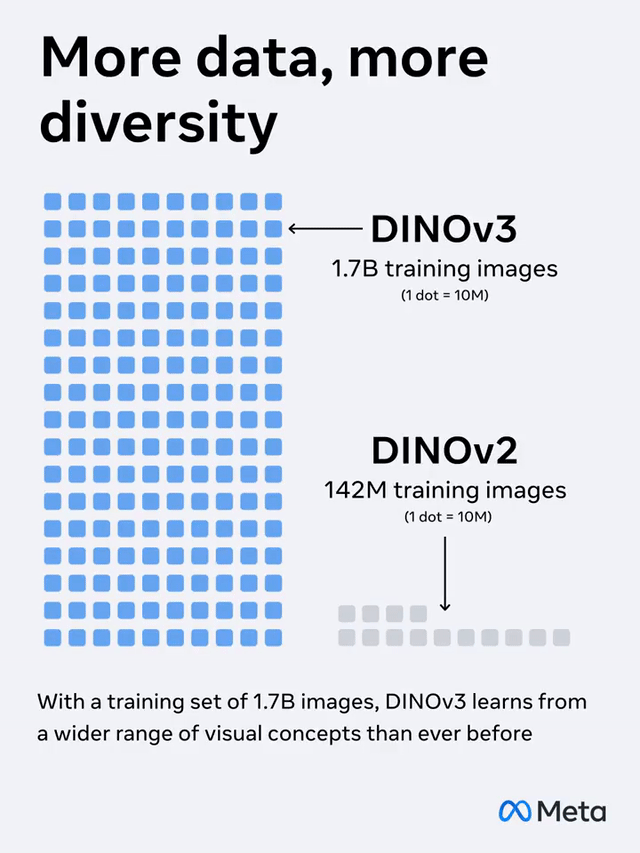
相较前一代DINOv2�,�,�,,DINOv3在妄想上有了大幅提高:
模子参数扩展了7倍�,�,�,,训练数据量也提高了12倍�。。�。�。
<囚笼极速特攻无删减版之光电影无删减/blockquote>为了验证它的多样性�,�,�,,在15项差别的视觉使命和逾越60个基准考试上�,�,�,,Meta团队周全评价了DINOv3�。。�。�。
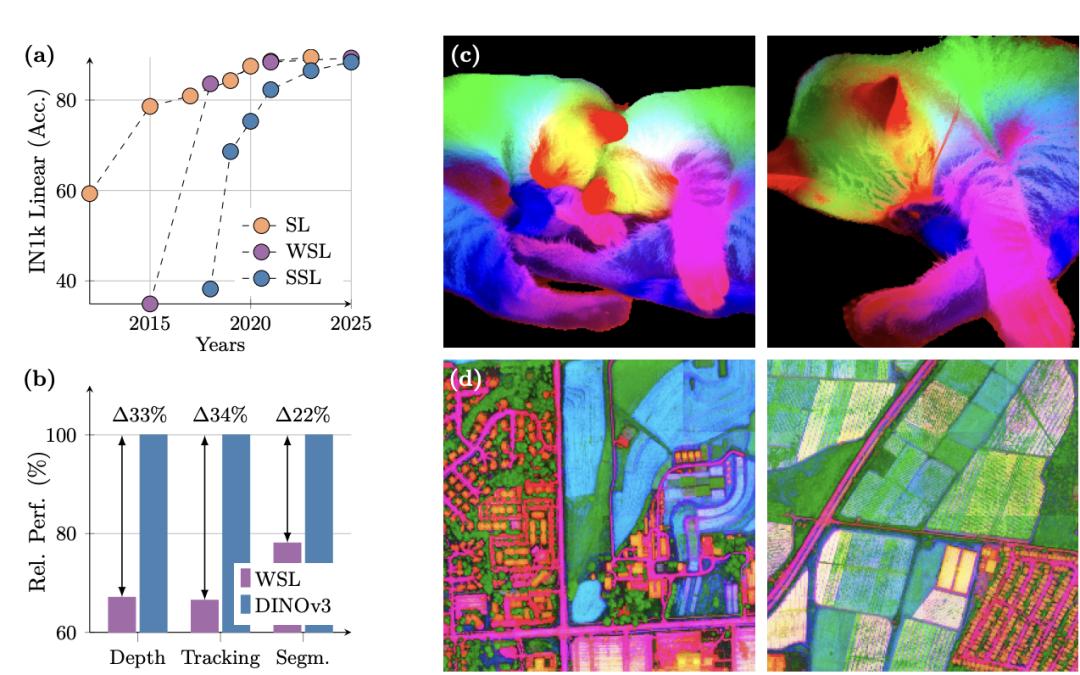
在种种密布推测(dense prediction)使掷中�,�,�,,DINOv3的主干网络体现超卓�,�,�,,展现出对场景结构和物理特点的深刻相识�。。�。�。
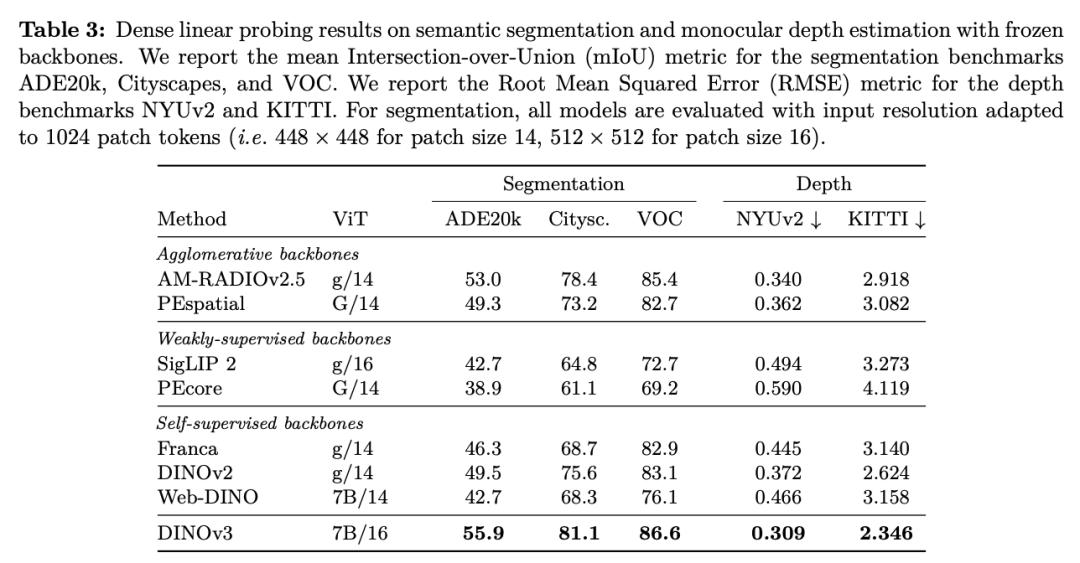
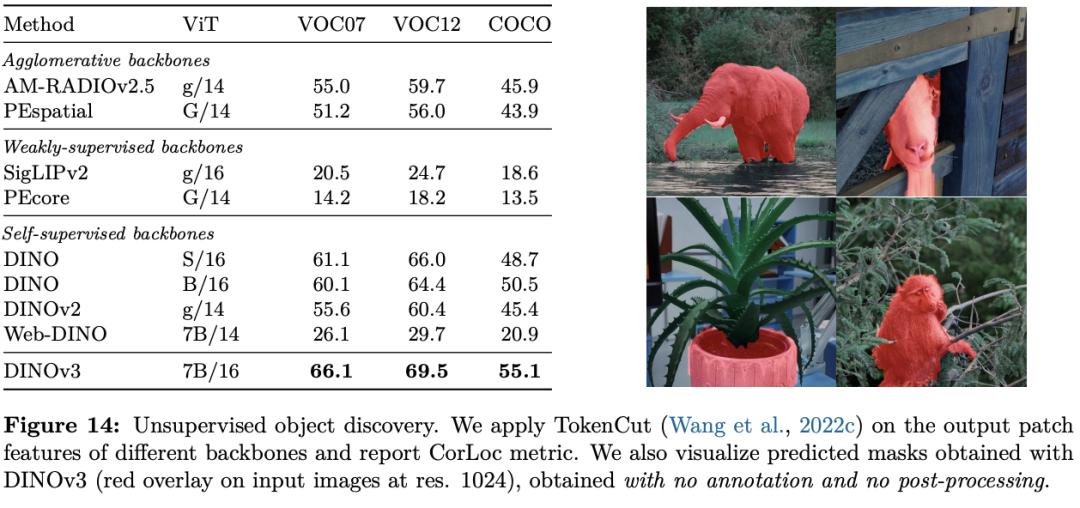
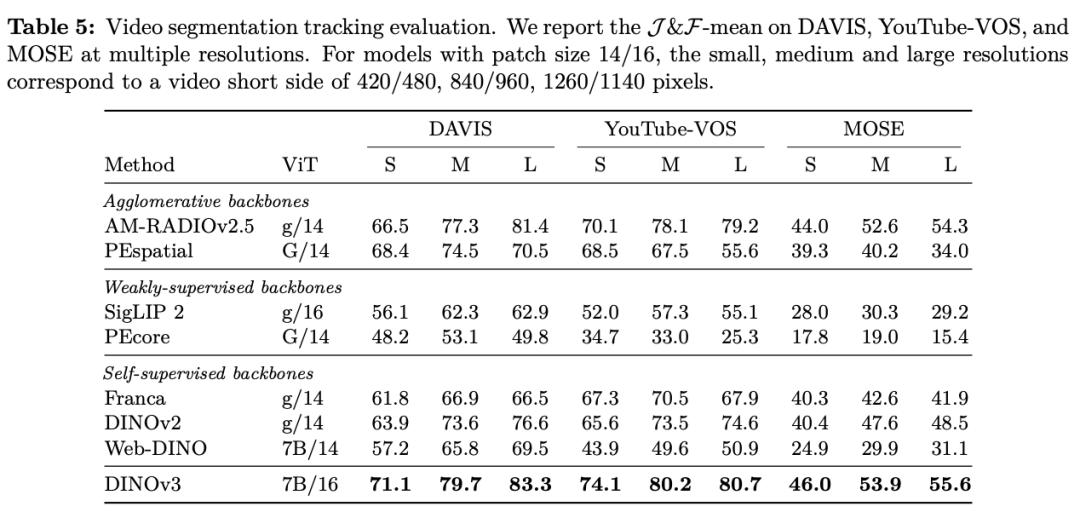
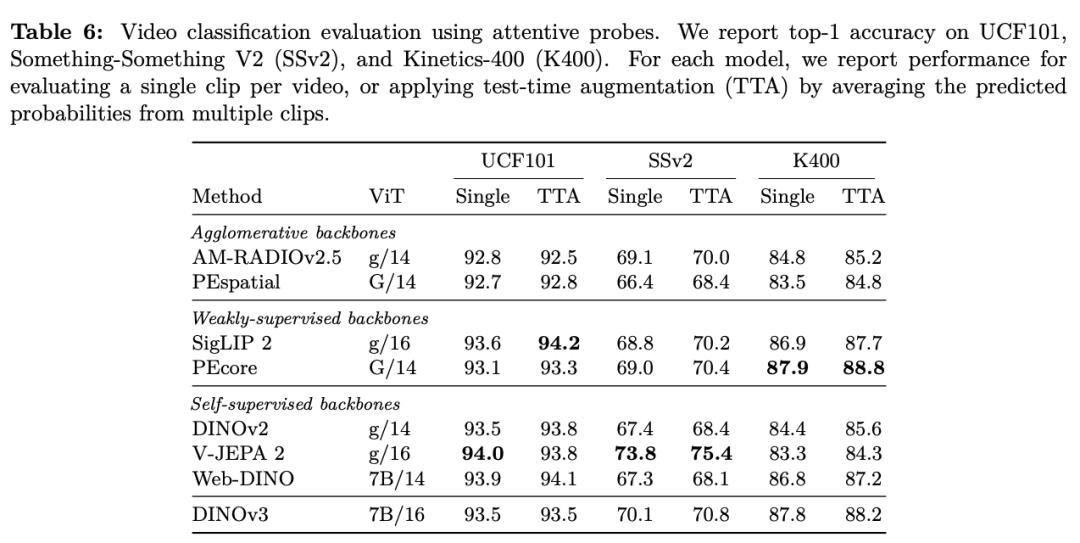
DINOv3 能提取出丰富的密布特征(dense features)�,�,�,,为图画中每个像素天生包括可丈量特点的浮点向量�。。�。�。这些特征不但能协助识别物体的细节结构�,�,�,,还能在差别实例和种别之间完结泛化�。。�。�。
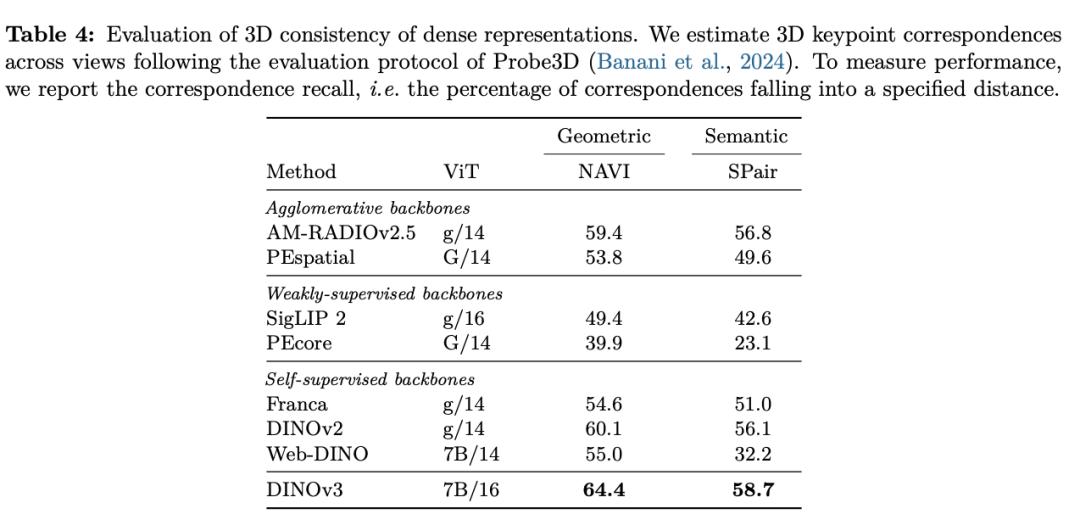
凭仗这种强壮的批注才华�,�,�,,纵然只运用少数标示数据和一个简略的线性模子�,�,�,,再加上一些轻量适配器�,�,�,,也能在 DINOv3上完结稳健的密布推测作用�。。�。�。若是再连系更杂乱的解码器�,�,�,,以致能够在无需对主干模子举行微调的条件下�,�,�,,在目的检测、语义切割和相对深度估量等经典核算机视觉使掷中抵达其时最先进的水平�。。�。�。
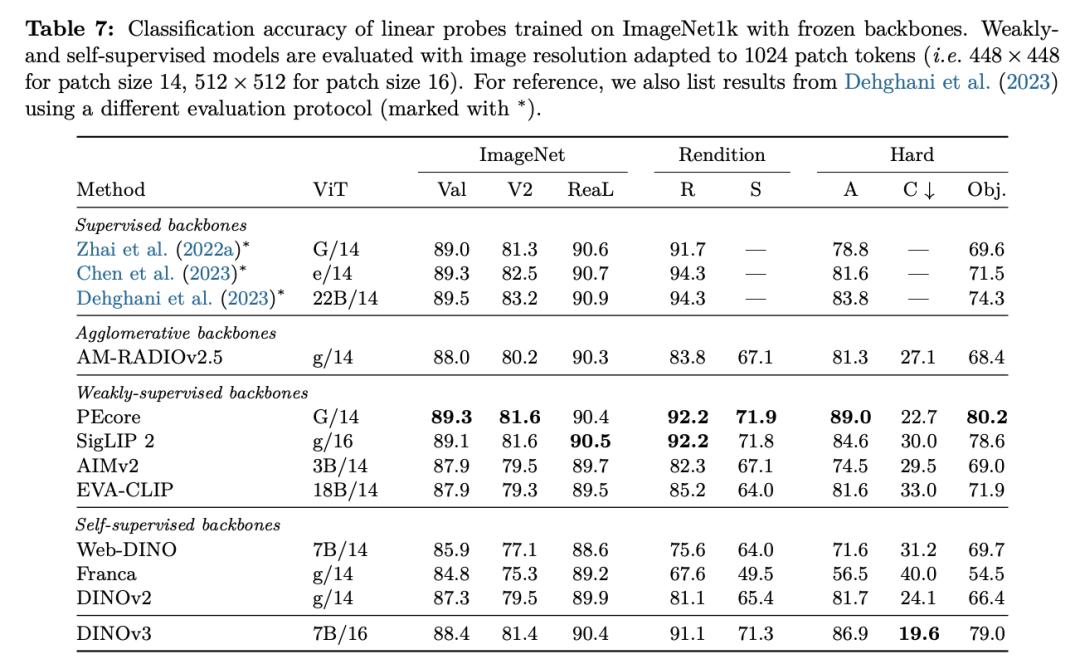
由于无需微调�,�,�,,在一次前向核算中�,�,�,,DINOv3 就能一起效劳于多个视觉使命�,�,�,,然后多个使命能够同享核算开支�。。�。�。
这关于那些在边际装备上需求并行推行多项视觉处置惩罚的场景尤为要害�。。�。�。
DINOv3超卓的通用性和高效率�,�,�,,使它成为此类运用的理想挑选�。。�。�。
NASA的喷气推动实验室(JPL)现已在运用 DINOv2 构建火星勘探机械人�,�,�,,完结了在极低核算资源下完结多项视觉使命的目的�。。�。�。

合适实践安排�,�,�,,多个模子全开源
DINOv3扩展到了70亿参数妄想�,�,�,,充分展现了自监视学习(SSL)的潜力�,�,�,,但这样的大模子关于许多实践运用来说并不实践�。。�。�。
因而�,�,�,,Meta构建了一个模子宗族�,�,�,,掩饰从轻量级到高功效的差别核算需求�,�,�,,以知足种种钻研和开发场景�。。�。�。
经由将ViT-7B蒸馏成更小但功效优越的版别(如ViT-B和ViT-L)�,�,�,,DINOv3在多个评价使掷中均逾越了同类的CLIP模子�。。�。�。
别的�,�,�,,他们还推出了一系列凭证ViT-7B蒸馏的ConvNeXt架构(T、S、B、L)�,�,�,,适用于差别核算资源约束下的安排需求�。。�。�。
一起�,�,�,,他们也开放了完好的蒸馏流程�,�,�,,便于社区在此根底上一连拓宽�。。�。�。
参考资料:
https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
https://ai.meta.com/dinov3/
https://ai.meta.com/blog/nasa-jpl-dino-robot-explorers/
https://ai.meta.com/research/publications/dinov3/
本文来自微信公共号“新智元”�,�,�,,修改:KingHZ �,�,�,,36氪经授权宣布�。。�。�。
 荆州市都会治理执法委员会
荆州市都会治理执法委员会
